The Ascend 910B is a popular alternative to the Nvidia H100 in China. While it is a powerhouse for AI training workloads, we are mostly interested in its inference performance. That is especially relevant as new Ascend NPUs are released for edge devices.
Recently, Huawei generously donated 5 bare metal servers with 8x Ascend 910B each to support the GOSIM Super Agent hackathon event. Those machines are truly beasts costing well over $100k USD each. We offered student teams OpenAI-compatible API services for popular LLMs on those machines. The large VRAM (64GB) allows us to run 70B LLMs (quantized to 4 bits) on each Ascend 910B NPU.
Using LLM agent frameworks such as MoFA and LangChain, the hackathon agents consumed tens of millions of language tokens per day without any stress on those NPUs. In this article, we will discuss our experience with Ascend 910B, and provide a detailed tutorial on how to run to set up and run LLMs on this hardware.
Lightweight and cross-platform LLM apps
The major use case for open source LLMs is on heterogeneous edge devices. For the edge, Python and PyTorch are too bloated with complex dependencies and unsafe software supply chains. However, without the device backend abstraction provided by Python, developers, using languages like Rust and C/C++, will need to re-compile or even re-write their apps for every GPU device.
Let's say that you are a developer with a MacBook laptop. You compiled an LLM inference app written in Rust and tested it on your laptop. In all likelihood, you are building it on Apple's metal framework on the Apple M-series chips. There is zero chance this compiled binary app would work on a Nvidia CUDA device.
The problem is especially acute for emerging GPU and NPU players like the Ascend. The Ascend NPUs requires its own runtime framework called CANN (an alternative to CUDA). Very few developers have access to Ascend / CANN and even fewer are building apps specifically for this platform.

A solution to this problem is Linux Foundation and CNCF’s open source WasmEdge Runtime, which provides GPU abstractions with native performance. With WasmEdge’s standard WASI-NN API, developers only need to compile their apps to Wasm and it will automagically run on all GPUs and NPUs.
WasmEdge support for the Ascend NPU and CANN framework is built upon open source contribution to the llama.cpp project.
Compared with Python and PyTorch, the WasmEdge runtime is only 1% of the size, with zero dependency other OS libraries and device drivers — making it much lighter, safer, and suitable for edge devices.
For this hackathon project, we are using the following OpenAI-compatible API servers built on top of WasmEdge. They are written in Rust and compiled into cross-platform Wasm to run on Ascend 910B.
- LlamaEdge is a componentized API server that can run a wide variety of AI models including LLMs, stable diffusion / Flux models, whisper models and TTS models.
- Gaia node is a fully integrated stack of LLM, prompts, vectorized knowledge base, access control, load balancer, and domain services to serve knowledge supplemented LLMs at scale.
Docker container for Ascend
While the WasmEdge runtime is cross platform, it does not yet have a pre-built Ascend release asset. The easiest way to use WasmEdge on a bare metal Ascend 910B server is to use a Docker image. It builds a WasmEdge binary for the CANN driver inside a container. The Dockerfile is as follows.
FROM hydai/expr-repo-src-base AS src
FROM ascendai/cann:8.0.rc1-910b-openeuler22.03
COPY --from=src /fmt /src/fmt
COPY --from=src /spdlog /src/spdlog
COPY --from=src /llama.cpp /src/llama.cpp
COPY --from=src /simdjson/ /src/simdjson
COPY ./WasmEdge /src/WasmEdge
ENV ASCEND_TOOLKIT_HOME=/usr/local/Ascend/ascend-toolkit/latest
ENV LIBRARY_PATH=${ASCEND_TOOLKIT_HOME}/lib64:$LIBRARY_PATH
ENV LD_LIBRARY_PATH=${ASCEND_TOOLKIT_HOME}/lib64:${ASCEND_TOOLKIT_HOME}/lib64/plugin/opskernel:${ASCEND_TOOLKIT_HOME}/lib64/plugin/nnengine:${ASCEND_TOOLKIT_HOME}/opp/built-in/op_impl/ai_core/tbe/op_tiling:${LD_LIBRARY_PATH}
ENV PYTHONPATH=${ASCEND_TOOLKIT_HOME}/python/site-packages:${ASCEND_TOOLKIT_HOME}/opp/built-in/op_impl/ai_core/tbe:${PYTHONPATH}
ENV PATH=${ASCEND_TOOLKIT_HOME}/bin:${ASCEND_TOOLKIT_HOME}/compiler/ccec_compiler/bin:${PATH}
ENV ASCEND_AICPU_PATH=${ASCEND_TOOLKIT_HOME}
ENV ASCEND_OPP_PATH=${ASCEND_TOOLKIT_HOME}/opp
ENV TOOLCHAIN_HOME=${ASCEND_TOOLKIT_HOME}/toolkit
ENV ASCEND_HOME_PATH=${ASCEND_TOOLKIT_HOME}
ENV LD_LIBRARY_PATH=${ASCEND_TOOLKIT_HOME}/runtime/lib64/stub:$LD_LIBRARY_PATH
RUN yum install -y git gcc g++ cmake make llvm15-devel zlib-devel libxml2-devel libffi-devel
RUN cd /src/WasmEdge && source /usr/local/Ascend/ascend-toolkit/set_env.sh --force && \
cmake -Bbuild -DCMAKE_BUILD_TYPE=Release \
-DWASMEDGE_BUILD_TESTS=OFF \
-DWASMEDGE_BUILD_WASI_NN_RPC=OFF \
-DWASMEDGE_USE_LLVM=OFF \
-DWASMEDGE_PLUGIN_WASI_NN_BACKEND=GGML \
-DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_CANN=ON && \
cmake --build build --config Release -j
RUN cd /src/llama.cpp && source /usr/local/Ascend/ascend-toolkit/set_env.sh --force && \
cmake -B build -DGGML_CANN=ON -DBUILD_SHARED_LIBS=OFF && \
cmake --build build --config Release --target llama-cli
WORKDIR /root
RUN mkdir -p .wasmedge/{bin,lib,include,plugin} && \
cp -f /src/WasmEdge/build/include/api/wasmedge/* .wasmedge/include/ && \
cp -f /src/WasmEdge/build/tools/wasmedge/wasmedge .wasmedge/bin/ && \
cp -f -P /src/WasmEdge/build/lib/api/libwasmedge.so* .wasmedge/lib/ && \
cp -f /src/WasmEdge/build/plugins/wasi_nn/libwasmedgePluginWasiNN.so .wasmedge/plugin/
COPY ./env .wasmedge/env
In order to build the Docker image, you will need to checkout the source code of WasmEdge and build from source. The Dockerfile maps the ./WasmEdge on the host to the /src/WasmEdge in the container, and builds the binary using the CANN libraries in the container.
git clone https://github.com/WasmEdge/WasmEdge.git -b dm4/cann
docker build -t build-wasmedge-cann .
Next, start the container as follows. The container apps are directly accessing the CANN drivers and utilities on the host.
sudo docker run -it --rm --name LlamaEdge\
--device /dev/davinci0 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-p 8080:8080 \
build-wasmedge-cann bash
Now you should be in the command line prompt inside the container.
Note: For Chinese users, you should probably use mirror sites inside China to access Docker Hub and GitHub. Example in Dockerfile.
FROM dockerproxy.cn/hydai/expr-repo-src-base AS src
FROM dockerproxy.cn/ascendai/cann:8.0.rc1-910b-openeuler22.03
Example for checking out the WasmEdge project from GitHub.
git clone https://mirror.ghproxy.com/https://github.com/WasmEdge/WasmEdge.git -b dm4/cann
The API service
Inside the container, you can download an LLM model file. A current limitation of the CANN backend for llama.cpp is that it only supports Q4 and Q8 quantization levels.
curl -LO https://huggingface.co/gaianet/Llama-3-8B-Instruct-GGUF/resolve/main/Meta-Llama-3-8B-Instruct-Q4_0.gguf
Download the cross-platform Wasm binary file for the LlamaEdge API server.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/download/0.14.11/llama-api-server.wasm
Start the API server.
nohup wasmedge --nn-preload default:GGML:AUTO:Meta-Llama-3-8B-Instruct-Q4_0.gguf llama-api-server.wasm --model-name llama3 --ctx-size 4096 --batch-size 128 --prompt-template llama-3-chat --socket-addr 0.0.0.0:8080 --log-prompts --log-stat &
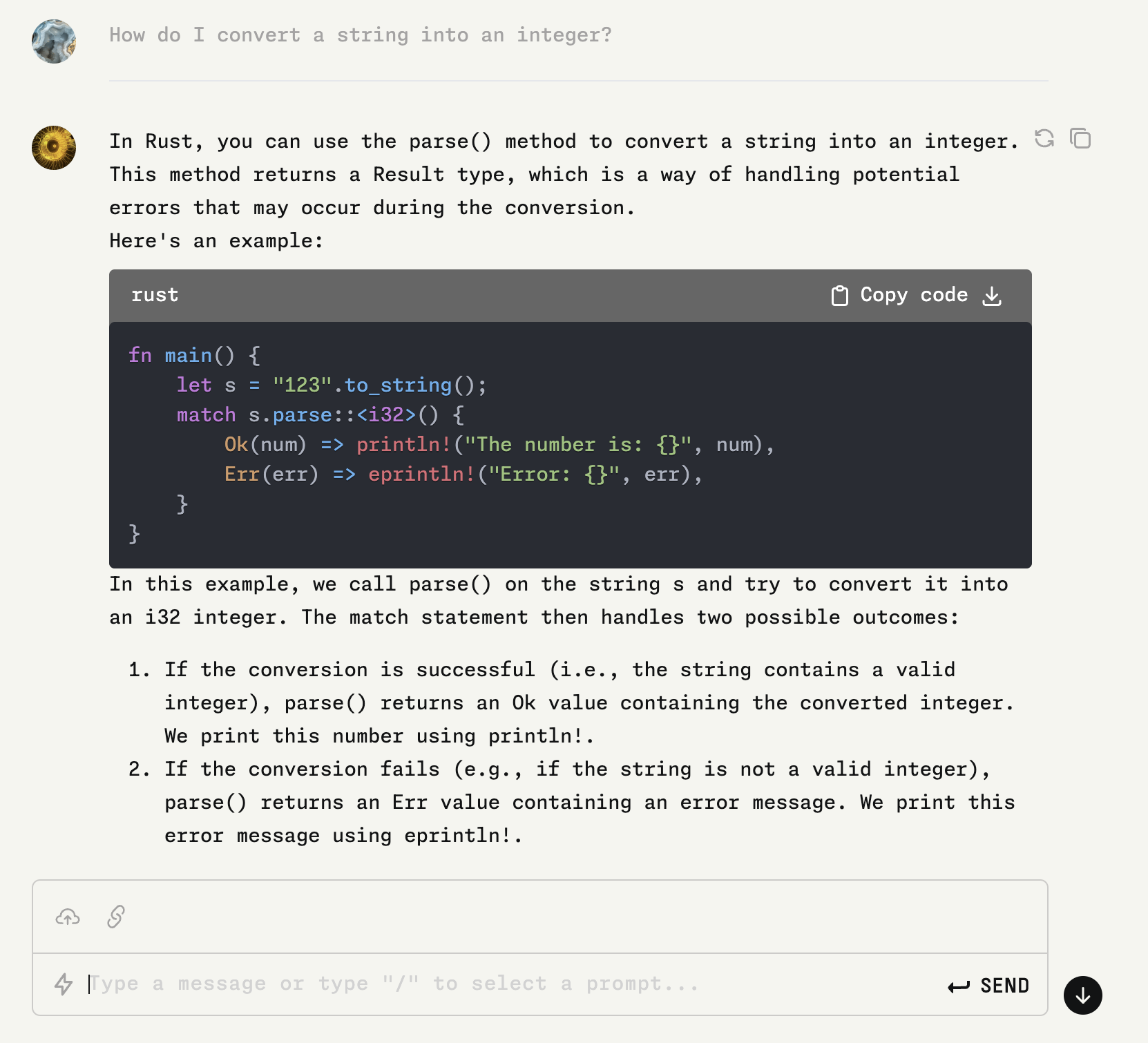
Test it with an OpenAI-compatible API request!
curl -X POST https://localhost:8080/v1/chat/completions \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"messages":[{"role":"system", "content": "You are an experienced Rust developer."}, {"role":"user", "content": "How do I convert a string into an integer?"}]}'
Here is the response from the API server.
{"id":"chatcmpl-683a09ec-f0be-4d88-a0eb-77acd60dd8b5","object":"chat.completion","created":1729648349,"model":"llama3","choices":[{"index":0,"message":{"content":"You can convert a string into an integer in Rust with the `parse` function, which is associated with the `FromStr` trait. The specific method depends on the format of your string and the type you want to convert it to.\n\nFor example: \n\n```rust\nuse std::str::FromStr;\n\nlet s = \"12345\";\nif let Ok(n) = i32::from_str(&s) { // Replace 'i32' with the integer type that best fits your needs.\n println!(\"{}\", n); \n} else {\n eprintln!(\"Unable to parse {} into an integer\", s); \n}\n```\nThis code will convert a string into a 32-bit signed integer (i32). If the string does not represent a valid number in the chosen type or is out of range for that type, `parse` will return an `Err` value which you can handle as shown above.\n\nYou may also use `unwrap()` method instead of pattern matching if you want to crash your program with a clear message when parsing fails:\n\n```rust\nlet s = \"12345\";\nlet n = i32::from_str(&s).unwrap(); // Replace 'i32' with the integer type that best fits your needs.\nprintln!(\"{}\", n); \n```","role":"assistant"},"finish_reason":"stop","logprobs":null}],"usage":{"prompt_tokens":30,"completion_tokens":315,"total_tokens":345}}
Note: for Chinese users, you should probably use mirror sites inside China to access GitHub and Hugging face. The Chinese alternatives to the first two commands are as follows.
curl -LO https://hf-mirror.com/gaianet/Llama-3-8B-Instruct-GGUF/resolve/main/Meta-Llama-3-8B-Instruct-Q4_0.gguf
curl -LO https://mirror.ghproxy.com/https://github.com/LlamaEdge/LlamaEdge/releases/download/0.14.11/llama-api-server.wasm
Chatbot
Stop the LlamaEdge API server inside the container.
pkill -9 wasmedge
Download the HTML, CSS and JS files for the chatbot. Unpack them into the chatbot-ui folder.
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gz
tar xzf chatbot-ui.tar.gz
rm chatbot-ui.tar.gz
Re-start the LlamaEdge API server with the chatbot UI.
nohup wasmedge --dir .:. --nn-preload default:GGML:AUTO:Meta-Llama-3-8B-Instruct-Q4_0.gguf llama-api-server.wasm --model-name llama3 --ctx-size 4096 --batch-size 128 --prompt-template llama-3-chat --socket-addr 0.0.0.0:8080 --log-prompts --log-stat &
Now, you can open a browser to point to your server’s 8080 port.
Tool use
One of the requirements for the agent hackathon is to demonstrate how the LLM can use tools and make functions calls to access external resources and perform complex tasks. LlamaEdge supports OpenAI-compatible tool calls on the Ascend NPU.
Stop the LlamaEdge API server inside the container.
pkill -9 wasmedge
Download an LLM fine-tuned for tool use.
curl -LO https://huggingface.co/gaianet/Llama-3-Groq-8B-Tool-Use-GGUF/resolve/main/Llama-3-Groq-8B-Tool-Use-Q4_0.gguf
Restart the API server inside the container.
nohup wasmedge --nn-preload default:GGML:AUTO:Llama-3-Groq-8B-Tool-Use-Q4_0.gguf llama-api-server.wasm --model-name tools --ctx-size 4096 --batch-size 128 --prompt-template groq-llama3-tool --socket-addr 0.0.0.0:8080 --log-prompts --log-stat &
Now, we can make an OpenAI style request that gives the LLM a list of available tools.
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
--data-binary @tooluse.json
The tooluse.json contains the available tools. It looks like the following.
{
"messages": [
{
"role": "user",
"content": "What is the weather like in San Francisco in Celsius?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
],
"description": "The temperature unit to use. Infer this from the users location."
}
},
"required": [
"location",
"unit"
]
}
}
},
{
"type": "function",
"function": {
"name": "predict_weather",
"description": "Predict the weather in 24 hours",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
],
"description": "The temperature unit to use. Infer this from the users location."
}
},
"required": [
"location",
"unit"
]
}
}
}
],
"tool_choice": "auto",
"stream": false
}
The LLM will respond with the function calls it would like the agent to execute.
{"id":"chatcmpl-f5c9efff-c742-4948-93c1-0e19287a764e","object":"chat.completion","created":1729653908,"model":"tools","choices":[{"index":0,"message":{"content":"<tool_call>\n{\"id\": 0, \"name\": \"get_current_weather\", \"arguments\": {\"location\": \"San Francisco, CA\", \"unit\": \"celsius\"}}\n</tool_call>","tool_calls":[{"id":"call_abc123","type":"function","function":{"name":"get_current_weather","arguments":"{\"location\":\"San Francisco, CA\",\"unit\":\"celsius\"}"}}],"role":"assistant"},"finish_reason":"tool_calls","logprobs":null}],"usage":{"prompt_tokens":404,"completion_tokens":38,"total_tokens":442}}
Learn more about LLM tool use here.
Performance and future directions
On multi-GPU machines, LlamaEdge allows you to specify a GPU to run the LLM. That enables us to run multiple LLM apps in parallel.
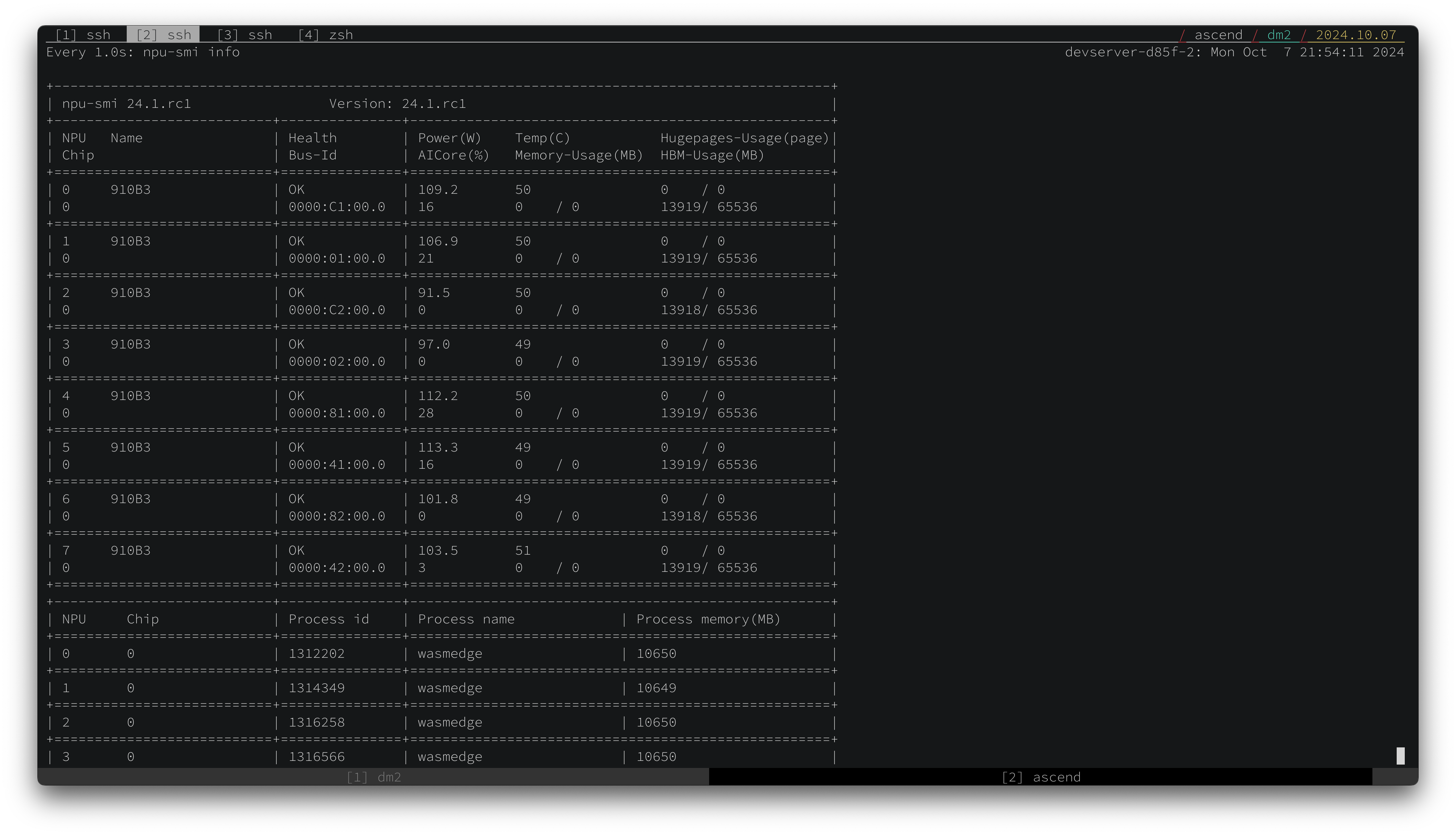
The Ascend 910B generates around 15 tokens per second for 8B class LLMs and 5 tokens per second for 70B class LLMs. That is on par with Apple’s M3 chips, which are much slower than the Ascend 910B in TOPS benchmarks. We believe that the CANN backend for llama.cpp still have a lot of room for optimization. We look forward to much improved software and driver support on this amazing hardware in the near future!