The internlm2_5-7b-chat model, a new open-source model from SenseTime, introduces a 7 billion parameter base model alongside a chat model designed for practical applications. This model showcases exceptional reasoning capabilities, achieving state-of-the-art results in math reasoning tasks, outperforming competitors like Llama3 and Gemma2-9B. With a remarkable 1M context window, InternLM2.5 excels in processing extensive data, leading in long-context challenges such as LongBench. The model is also capable of tool use, integrating information from over 100 web sources, with enhanced functionalities in instruction adherence, tool selection, and reflective processes.

In this article, taking internlm2_5-7b-chat as an example, we will cover
- How to run this model locally and start a OpenAI-compatible API service
- Run a Obsidian-local-gpt Plugin on top of the started API server
We will use LlamaEdge (the Rust + Wasm stack) to develop and deploy applications for this model. There are no complex Python packages or C++ toolchains to install! See why we choose this tech stack.
Run internlm2_5-7b-chat locally and start a OpenAI-compatible API service
Step 1: Install WasmEdge via the following command line.
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s -- -v 0.13.5 --ggmlbn=b3259
Step 2: Download the internlm2_5-7b-chat GGUF file. Since the size of the model is 5.51G, it could take a while to download.
curl -LO https://huggingface.co/second-state/internlm2_5-7b-chat-GGUF/resolve/main/internlm2_5-7b-chat-Q5_K_M.gguf
Step 3: Download an API server app. It is also a cross-platform portable Wasm app that can run on many CPU and GPU devices.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
Step 4: use the following command lines to start an API server for the model.
wasmedge --dir .:. --nn-preload default:GGML:AUTO:internlm2_5-7b-chat-Q5_K_M.gguf \
llama-api-server.wasm \
--prompt-template chatml \
--ctx-size 500000 \
--batch-size 256 \
--model-name internlm2_5-7b-chat
From another terminal, you can interact with the API server using curl.
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept:application/json' \
-H 'Content-Type: application/json' \
-d '{"messages":[{"role":"system", "content": "You are a sentient, superintelligent artificial general intelligence, here to teach and assist me."}, {"role":"user", "content": "Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world."}], "model":"internlm2_5-7b-chat"}'
Full API Server with Obsidian-local-gpt Plugin
The LlamaEdge will build an OpenAI compatible API server the open source LLM you’re running. This allows you to integrate A full API server setup with internlm2_5-7b-chat enables powerful, local language model capabilities within the Obsidian note-taking application, enhancing user experience with AI-powered features like text generation, summarization, spelling check and more.
Make sure you have already installed the Obsidian app on your device.
Install the Obsidian-local-gpt Plugin
- Open Obsidian settings, navigate to “Community plugins”, and search for
obsidian-local-gpt. - Install the plugin by clicking “Install”.
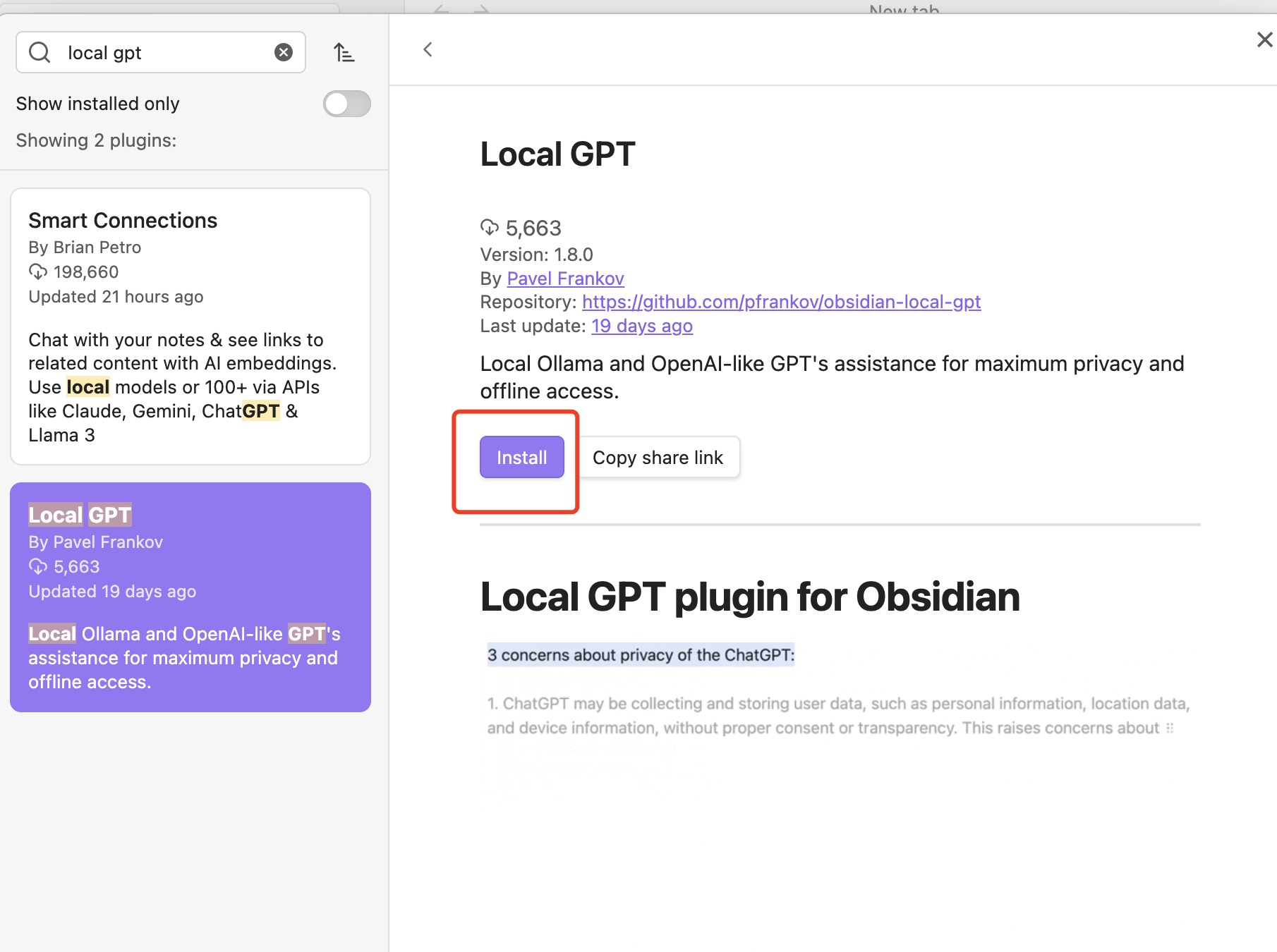 Then click “Enable”.
Then click “Enable”.
Configure the Plugin
- Go to the plugin settings.
- Select “AI Provider” as “OpenAI compatible server”.
- Set the server URL. Use http://localhost:8080/ if you are running a local LLM.
- Configure API key to LLAMAEDGE
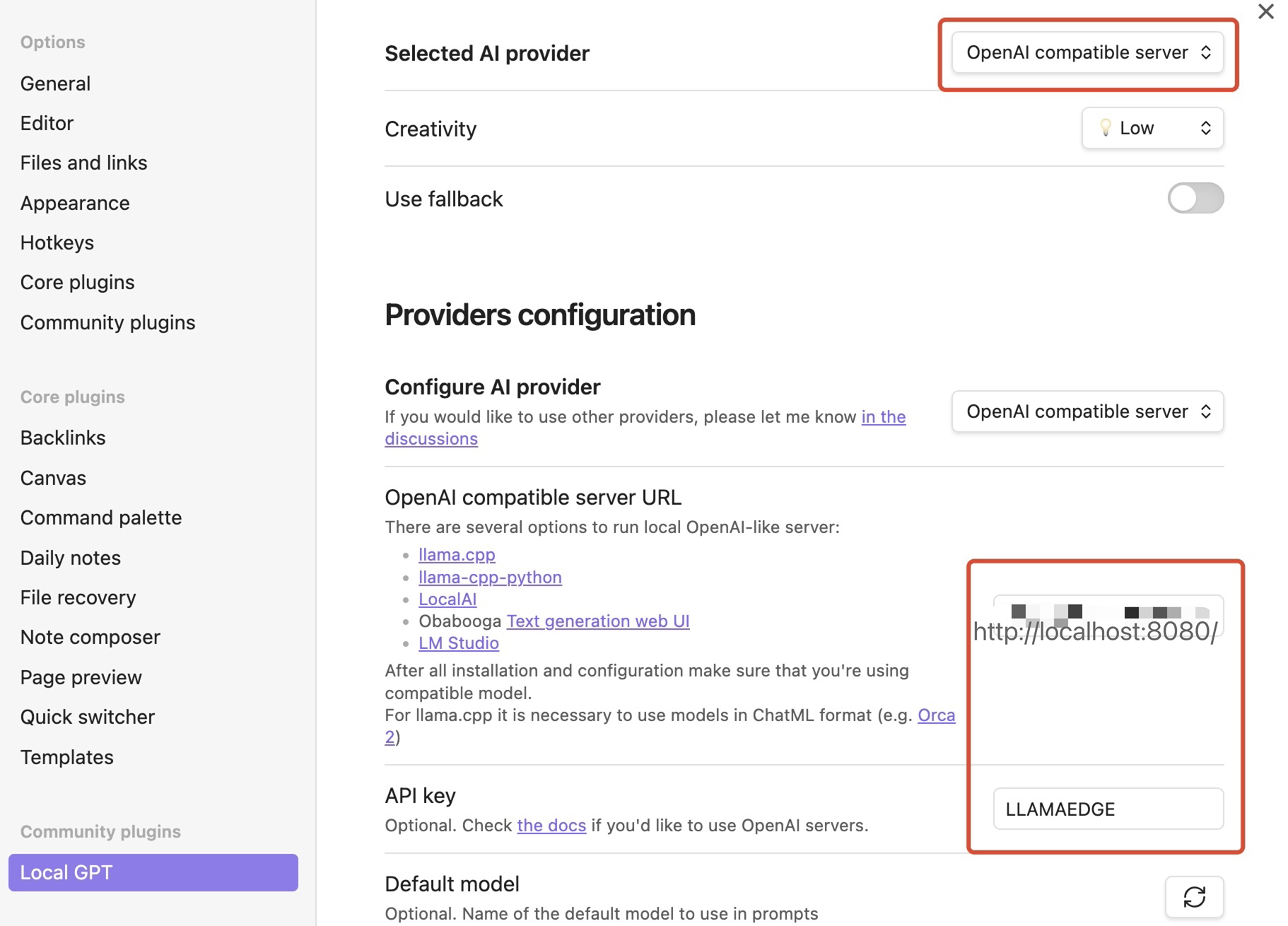 Under the default model, make sure to click the refresh button and choose the internlm2_5-7b-chat model.
Under the default model, make sure to click the refresh button and choose the internlm2_5-7b-chat model.
Configure Obsidian Hotkey
- Open the Obsidian Settings
- Go to Hotkeys
- Filter “Local” and you should see “Local GPT: Show context menu”
- Click on
+icon and press hotkey (e.g.⌘ + M)
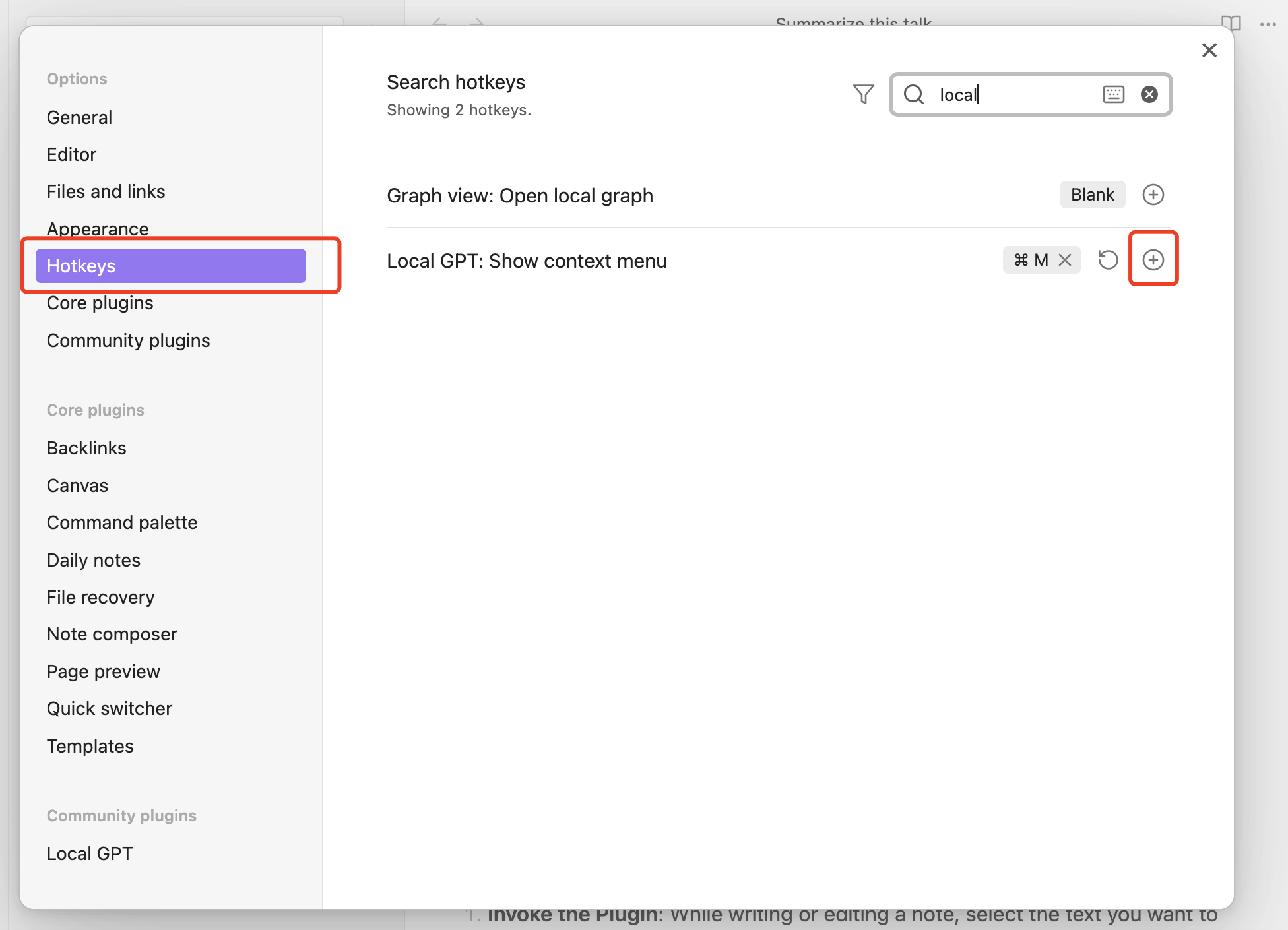
As long as you have set the hotkey, while writing or editing a note, select the text you want to interact with, and press the hotkey you have set to use this LLM powered plugin!
Use the Plugin
With the plugin configured, users can use AI functionalities directly within their Obsidian notes. They can generate content, summarize lengthy information, or extract tasks from their notes—all while ensuring that their data remains private and secure.
This integration provides a seamless experience for note-takers to augment their workflow with AI without compromising on privacy. It's particularly beneficial for researchers, students, and professionals who require robust note-taking capabilities complemented by AI.
Conclusion
The internlm2_5-7b-chat model exemplifies the adaptability of modern LLMs to various environments and needs. Whether a chatbot interface or empowering a note-taking application, internlm2_5-7b-chat stands out as a powerful tool for both developers and end-users. Its ability to be integrated into different software architectures opens up numerous possibilities for application in real-world scenarios.
This guide demonstrates just a couple of the potential applications, but the flexibility of internlm2_5-7b-chat allows for much more exciting developments in AI application. Join the WasmEdge discord to ask questions and share insights.