Gemma-3 is a lightweight, efficient language model developed by Google, part of the Gemma family of models optimized for instruction-following tasks. Designed for resource-constrained environments, Gemma-3 retains strong performance in reasoning and instruction-based applications while maintaining computational efficiency. Its compact size makes it ideal for edge deployment and scenarios requiring rapid inference.
This model achieves competitive results across benchmarks, particularly excelling in tasks requiring logical reasoning and structured responses.
We have quantized Gemma-3 in GGUF format for broader compatibility with edge AI stacks.
Gemma-3-1b-it-GGUF: https://huggingface.co/second-state/gemma-3-1b-it-GGUF
Gemma-3-4b-it-GGUF: https://huggingface.co/second-state/gemma-3-4b-it-GGUF
Gemma-3-12b-it-GGUF: https://huggingface.co/second-state/gemma-3-12b-it-GGUF
Gemma-3-27b-it-GGUF: https://huggingface.co/second-state/gemma-3-27b-it-GGUF
 In this article, we will cover how to run and interact with Gemma-3-1b-it-GGUF on your own edge device.
In this article, we will cover how to run and interact with Gemma-3-1b-it-GGUF on your own edge device.
We will use the Rust + Wasm stack to develop and deploy applications for this model. There are no complex Python packages or C++ toolchains to install! See why we choose this tech stack.
Run Gemma-3-1b-it-GGUF
Step 1: Install WasmEdge via the following command line.
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s -- -v 0.14.1
Step 2: Download the Quantized Model
The model is 851MB in size and should be ready soon. If you want to run a different model, you will need to change the model download link below.
curl -LO https://huggingface.co/second-state/gemma-3-1b-it-GGUF/resolve/main/gemma-3-1b-it-Q5_K_M.gguf
Step 3: Download the LlamaEdge API server
It is a cross-platform portable Wasm app that can run on many CPU and GPU devices.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
Step 4: Download the Chatbot UI to interact with the Gemma 3 model in the browser.
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gz
tar xzf chatbot-ui.tar.gz
rm chatbot-ui.tar.gz
Next, use the following command lines to start a LlamaEdge API server for the model. LlamaEdge provides an OpenAI compatible API, and you can connect any chatbot client or agent to it!
wasmedge --dir .:. --nn-preload default:GGML:AUTO:gemma-3-1b-it-Q5_K_M.gguf \
llama-api-server.wasm \
--prompt-template gemma-3 \
--ctx-size 128000 \
--model-name gemma-3-1b
Gemma-3 series models don’t support system prompt. But with LlamaEdge, you can set a system prompt for your Gemma-3 model.
Chat
Visit http://localhost:8080 in your browser to interact with Gemma-3!
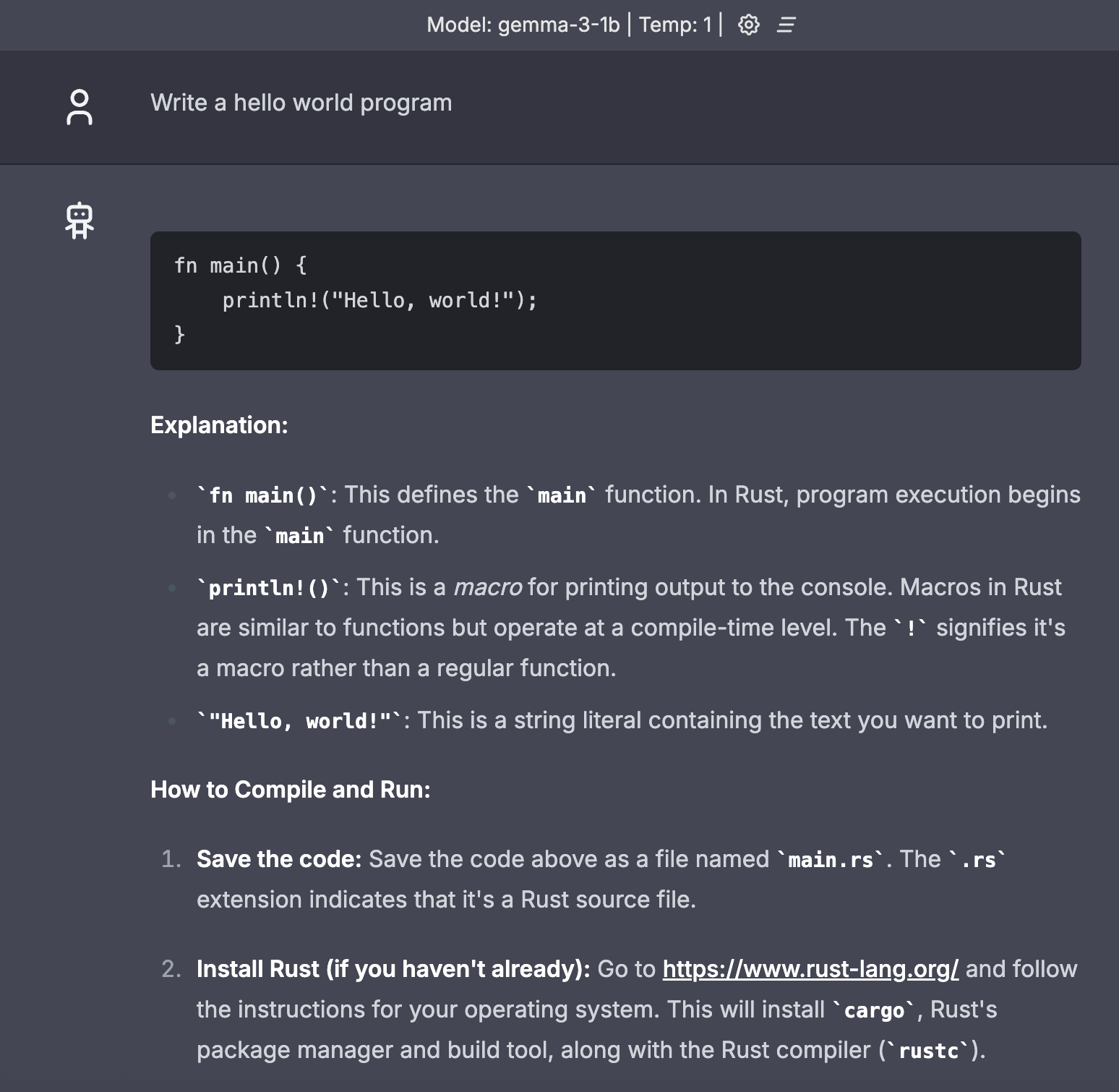
As you can see, the system prompt works.
Use the API
The LlamaEdge API server is fully compatible with OpenAI API specs. You can send an API request to the model.
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept:application/json' \
-H 'Content-Type: application/json' \
-d '{"messages":[{"role":"system", "content": "You are a helpful assistant. Answer as concise as possible"}, {"role":"user", "content": "Can a person be at the North Pole and the South Pole at the same time??"}], "model": "Gemma-3-1b"}'
{"id":"chatcmpl-809db913-3efb-47e1-99eb-779917e5545f","object":"chat.completion","created":1742307745,"model":"gemma-3-1b","choices":[{"index":0,"message":{"content":"No, a person cannot be at both the North Pole and the South Pole simultaneously. They are located on opposite hemispheres of the Earth.","role":"assistant"},"finish_reason":"stop","logprobs":null}],"usage":{"prompt_tokens":38,"completion_tokens":29,"total_tokens":67}}%
RAG and Embeddings
Finally, if you are using this model to create agentic or RAG applications, you will likely need an API to compute vector embeddings for the user request text. That can be done by adding an embedding model to the LlamaEdge API server. Learn how this is done.
Gaia
Alternatively, the Gaia network software allows you to stand up the Mistral LLM, embedding model, and a vector knowledge base in a single command. Try it with Gemma 3-1b-it-GGUF!
Join the WasmEdge discord to share insights. Any questions about getting this model running? Please go to second-state/LlamaEdge to raise an issue or book a demo with us to enjoy your own LLMs across devices!